
BUAA-OS-2023-Lab1-Report
BUAA-OS-2023-Lab1-Report
Thinking 1.1
不使用交叉编译,使用gcc -c对文件进行编译,对编译而尚未链接的文件进行反汇编可以得到以下代码:
git@21371068:~/21371068/tools/readelf (lab1)$ gcc -c hello.c |
不使用交叉编译,对编译出的可执行文件直接进行objdump -DS指令,可以得到以下代码:
git@21371068:~/21371068/tools/readelf (lab1)$ gcc hello.c -o hello2 |
如使用交叉编译mips-linux-gnu-gcc hello.c进行编译链接,并直接使用objdump -DS进行反汇编,则会返回如下代码:
git@21371068:~/21371068/tools/readelf (lab1)$ objdump a.out -DS |
出现如上错误是因为,需要使用交叉编译链所对应的反汇编工具才能解析,在我们的实验环境下就是mips-linux-gnu-objdump
git@21371068:~/21371068/tools/readelf (lab1)$ mips-linux-gnu-objdump -DS hello.o |
objdump参数意义
-D 反汇编文件中的所有section(节) |
Thinking 1.2
使用我们编写的readelf程序对内核文件检查后得到的视图如下:

使用Linux系统内自带的readelf指令对readelf文件和hello文件进行分析(使用readelf -h readelf/hello指令)可以发现两个文件的类型不同:hello是ELF32类型,而readelf是ELF64类型

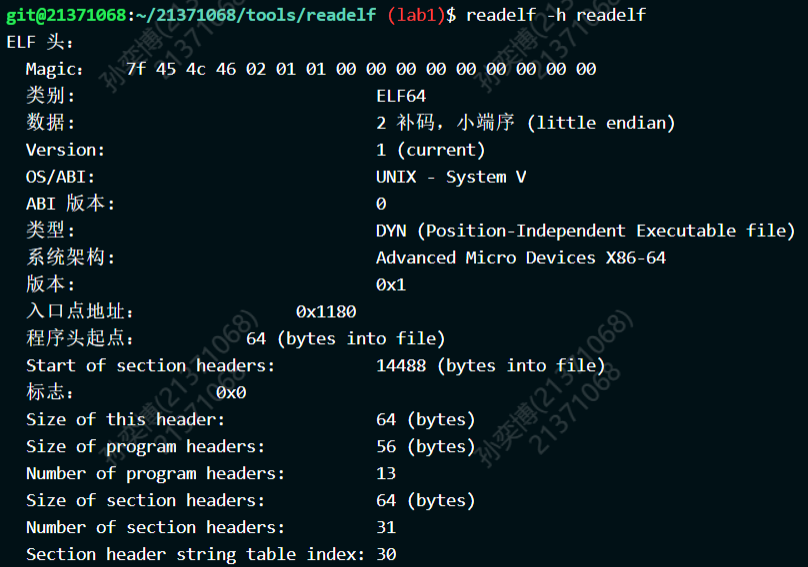
这说明我们的hello文件是32位的格式,而readelf则是64位的。我们打开readelf.c文件,发现其中的的数据类型前缀都是ELF32,也正是说明了这个程序负责分析32位的ELF文件。所以它不能分析身为64位格式程序的自己。
进入同目录下的Makefile文件查看,发现了两个文件在编译方式上的不同:

查阅相关资料后得知参数-m32:编译出来的是32位程序,既可以在32位操作系统运行,又可以在64位操作系统运行。这也恰好印证了readelf指令对于这两个文件的类型判定。
补充:大小端转换
//小端->大端: |
Thinking 1.3
在我们的实验中,系统启动被简化成了把内核加载到指定内存位置。
MIPS系统启动时首先接管的是bootloader,随后Linker Script把各个节映射到对应的段上,内核文件也在这时被加载到合适的地址空间中。
在Exercise 1.2中,我们补全了kernel.lds文件,把.text、.data、.bss三个段映射到了合理空间
/* Exercise 1.2 Your code here. */ |
经过Linker Script文件的引导,内核代码就会被加载到0x80010000这段地址。再通过ENTRY(_start)的入口规定,如此便保证了我们能够跳转到内核入口
Exercise 1.1
C语言指针
在Exercise 1.1中,我们需要使用指针对ELF头进行寻址后取值,那么这时使用指针取得合适的地址就是重点了
C语言对指针的加法运算符进行了重载
如果使用了+对地址进行运算,地址的位移量会自动根据加号前的数据结构调整。
Struct st * p = (Struct st*)p + a |
具体为:地址会向后移动a*sizeof(Struct st)字节
在我们的实验中需要在ELF头中寻找到节头表的入口,需要的行为是:
const void *sh_table = (Elf32_Shdr *)(binary + ehdr->e_shoff); |
但是有的同学写成了
const void *sh_table = (Elf32_Shdr *)(ehdr + ehdr->e_shoff); |
原本的binary类型为const void *,它的加法运算符向后移动的单位为1字节;而已经转型为Elf32_Ehdr的ehdr重载后则会向后移动一个Elf32_Ehdr大小的地址空间。于是虽然两个指针指向了同一个地址,+后的值也相同,但是运算后得到的结果却截然不同
readelf.c文件的补全
实验目的为输出ELF文件的节头地址信息。
首先需要明确,我们需要的节头地址信息保存在节头表中每个项目的特定字段中(Elf32_Shdr -> sh_addr)。并且这个sh_addr指向ELF文件中的每个节头所在地址。那么就需要我们从ELF表头访问到节头表,并对每一项遍历即可。
遍历每一个节头的方法是:先读取节头的大小,随后以指向第一个节头的指针(即节头表第一项的地址)为基地址,不断累加得到每个节头的地址。
具体实现为根据Elf32_Edhr -> e_shoff寻找到节头表入口地址、根据Elf32_Edhr -> e_shnum获取节头表中所含有项的个数,并根据Elf32_Edhr -> e_shentsize获取节头表长度,便于位移
const void *sh_table; |
Exercise 1.2
Linker Script
Linker Script中记录了各个节应该如何映射到段,以及各个段应该被加载到的位置。
在Exercise 1.2中,我们就要利用Linker Script,对内核文件的各节进行内存指派,找到对应节的地址。段是由节所结合组成的,因为节的位置改变了,所以段的地址也会相应地发生移动,具体实现如下:
SECTIONS |
其中的.号用作定位计数器,通过设置.的地址,声明接下来的节会被按序安放在该地址后。(在SECTIONS中,默认初始的地址为0地址,所以需要先修改地址然后再安排节文件)
后面的代码如.bss:{*(.bss)},表示将所有输入文件中的.bss节(右边
的.bss)都放到输出的.bss节(左边的.bss)中。
观察kernel.lds的其他代码,还能发现这个文件规定了程序的入口地址。我们的实验程序通过ENTRY(_start)设置_start函数作为入口地址开始运行
/* |
而_start函数被安放在/init/start.S文件中
Exercise 1.3
_start函数的设置
.text |
在mmu.h文件中我们可以查询到系统内核各部分内存分配情况,这里就能找到栈顶地址为0x80400000
设置结束后汇编程序完成,就可以跳转入C语言的函数入口mips_init了
我们使用
jal、j指令进行函数的跳转。在不同文件链接时,链接器回对目标文件中的符号(包括函数名)进行重定位,修改跳向这些函数的地址,实现跨文件的函数调用
printk函数的实现
printk函数实现功能,底层上依靠的是console.c文件中printcharc函数对控制台进行字符的输出;
向上一层,print.c中的vprintfmt函数则通过格式化字符的形式对console.c中的函数进行合理调用,实现输出;
再向上一层,就是printk.c这个文件,它接收输出参数,并把变长参数表和传递给vprintfmt函数,最终实现字符的输出。
变长参数表
stdarg.h头文件对变长参数表定义了一系列宏变量与变量类型:
-
va_list:变长参数表对应的变量类型 -
va_start(va_list ap, lastarg):初始化变长参数表 -
va_arg(ca_list ap, 类型):去除变长参数表的下一个参数 -
va_end(va_list ap):结束变长参数表的使用
声明方式:
va_list ap;// 声明变长参数表 |
回到我们的printk函数:printk本身接受了外部传入的不定长参数,创建了一个变长参数表,传入了vprintfmt函数
// printcharc |
具体实现不再说明
心得体会
- 第一次完成
lab1内容时还不能理解内核为什么能正常工作、函数为何能正常运行,只是按照指导书的说明进行补充而已。而恰是这个不理解,成了实验过程中的最大难题。只有完成内容后,再重新回过头来审视每一步,才能知道每一步的具体功效,明白实验过程中“那里”为什么要“那么做”。经常性的回顾对实验过程理解很有必要。 - 完成实验过程中并没有查看除了需要填写代码文件以外的文件,然而,各个函数的实现过程与相关信息其实都藏在课程组为我们写好的其他文件中,读过一遍其他函数的定义、调用与功能,才让实验过程中填写的代码有理可据。





