
BUAA-X86Programming-1
X86汇编程序设计笔记-1
本系列是北航计算机学院于 2024 年春季学期开设的一般专业课《X86汇编程序设计》的学习笔记,由于学习过程中掌握并不牢靠,如有错误请读者不吝赐教!
基本知识
数制及数制间的转换
开摆!
二进制数与十六进制数的运算
开摆!
ASCII码和BCD码
- BCD 码:用二进制编码的十进制数,每一位数用四位二进制数表示
- ASCII 码:标准码有 128 个字符
IBM-PC计算机组织
本节以最基础的 Intel 8086/8088 为例进行学习,8086 的指令为 16 位,8088 为 8 位。
8088 和 8086 的体系结构和指令系统、指令编码格式、寻址方式完全相同,软件也完全兼容。
IBM-PC微型计算机的基本结构
- 可直接寻址的内存:$2^{20}=1MB$
- 地址线有 20 根,但字长只有 16 位
Intel 8086 CPU 寄存器结构
Intel 8086/8088 CPU 主要由运算器、控制器以及工作寄存器三部分组成
通用寄存器
通用寄存器共有 8 个:AX、BX、CX、DX、SP、BP、SI、DI;
- 数据寄存器:前四个寄存器,可以拆分为两个 8 位的寄存器,即 AX→AH:AL
- AX:通常存储计算结果和操作数
- BX:间接寻址时存放基地址
- CX:循环指令、移位指令的计数器
- DX:双字乘除法运算的拓展寄存器;IO 指令中存放 IO 端口的地址
- 指针寄存器:后四个寄存器,主要用于存放地址(只有 BP 使用堆栈基地址)
- SP:栈指针寄存器,栈生长方式在堆栈一节再进行详细介绍
- BP:堆栈段的基址指针,和 BX 作用类似,用于传递参数
- SI:源变址寄存器,用作寻址的偏移量,不能和 DI 互换,某些指令会隐含指定所使用的寄存器
- DI:目的变址寄存器,同上
段寄存器
段是内存空间的一片区域,表示一个段需要使用段的基地址来进行表示
段寄存器存放对应段的基地址,但因为地址是20位的,所以寄存器仅存放了地址的高16位,具体地址可由低四位的偏移量以及公式推导得来
- 段:代码段、数据段、堆栈段、附加段
- 寄存器:CS、DS、SS、ES
指令指针寄存器
指令指针寄存器(IP)是一个专用的 16 位寄存器,它表示的是当前要执行的指令在代码段中的偏移地址(也就是实际地址相对于 CS 寄存器的偏移),在可使用的指令中,只有转移指令、子程序调用+返回指令、中断调用+返回指令三类指令能够主动修改 IP 的值。
标志寄存器可以暂且不考虑。
PC机的内存组织
- 内存大小:20 根地址线 → $2^{20}=1MB$
- 单字长 16 位,一个字由 2 字节构成
内存地址、字
在内存的排布中,需要遵守一些规则:
- 单字的地址是第 1 个字节的地址
- 单字存放在内存中时,低字节在低地址一侧,高字节在高地址一侧
- 双字存放在内存中时,低字在低地址一侧,高字在高地址一侧
内存地址的分段
前面提到了,内存地址划分为了段的基地址和段内的偏移地址,实际地址通过这两个地址来进行计算得到。
考虑到过大的段内地址使得内存分配十分浪费,过小的段内地址会进行频繁的段切换,使用段地址、段内地址均 16 位+二者重叠 12 位的做法能够更好地利用内存空间。
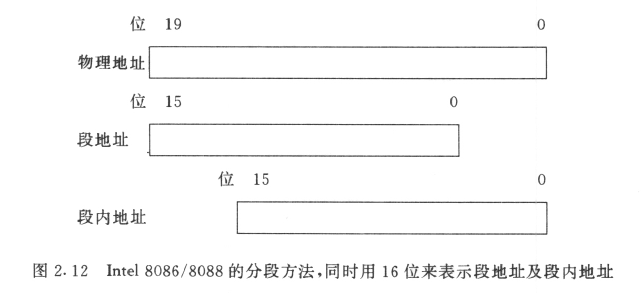
在这种分段方法中,总计可以分为 64K 个段,每一段又最多能拥有 64KB 的空间,给内存分配带来了灵活性。
物理地址和逻辑地址
在 8086 的体系中,也存在物理地址和逻辑地址之分。
- 逻辑地址:使用
段地址:段内地址的格式表示,前后均为 16 位二进制,可以表示地址在程序段中的逻辑位置 - 物理地址:没有分页与映射机制,所以直接使用逻辑地址就能得到物理地址(反之也成立)
物理地址的计算公式如下:
$$
段地址<<10H+段内地址=物理地址
$$
在这种地址处理机制下,逻辑地址和分段的灵活性使得一个物理地址可以对应多个逻辑地址
堆栈
堆栈结构
8086 中,堆栈的位置和大小是由 SS 和 SP 寄存器确定的:SS 寄存器保存栈的边界(栈自身增长的极限地址),SP 寄存器保存的是栈边界到当前栈顶地址的偏移量
也就是说,无论栈发生怎样的变化,SS 寄存器都不会发生改变;数据存取始终在 SS+SP 地址发生;存入数据时 SP 会减少,取出相反

在这个图中栈开始从 24100H 存放数据,一致增长到 24080H,SP 寄存器减少了 20H
堆栈操作
堆栈的操作遵守 FIFO 规则,操作分为压入和弹出两种,操作必须以单字为单位进行,不允许一次操作一个字节/双字。
寻址方式与指令系统
汇编语言程序由基本指令与基本伪指令组成,本节仅介绍部分指令
8086 指令的汇编语言格式与 mips 指令相似;但是机器语言格式区别较为明显,字长不同使得指令的字段变化十分明显。下面将对指令格式、指令系统和简单的寻址方式等进行介绍
指令格式
指令的汇编语言格式
8086/8088 指令由操作码和操作数两部分构成,表示为 OP DST, SRC。大部分指令有两个操作数,部分指令仅有单个操作数或无操作数。
当指令无操作数时,操作的对象一般是预定好的。例如 STD 指令无操作数,其功能是设置方向标志寄存器 DF 为 1。
指令的机器语言格式
8086/8088 的机器码格式相较于 mips 而言更复杂,一条指令的长度可以是 1-7 个字节,单条指令的前后字节都可能根据指令类型起到不同的作用。
可以将指令分为三段:操作码字节、寻址方式字节和段超越字节。
每个指令不一定都含有这三段,但是每一段都能起到对应的说明作用。
操作码字节
操作码字节一般只占用一个字节,表示本指令的操作和操作数的地址码。
根据指令的不同,操作码可以分为两种基本格式:
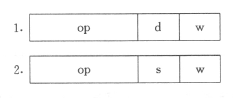
- d 位和 s 位分别在两个/一个操作数时有效:
- d 位(destination):指定位于寄存器中的操作数是目的操作数(d=1)还是源操作数(d=0)
- s 位(signed):控制立即数的扩展方式,s=1 时符号拓展、s=0 时零拓展
- w 位(word)表示本指令的操作对象是字(w=1)或字节(w=0)
寻址方式字节
寻址方式字节表示操作数的寻址方式,通常是指令的第二个字节,其定义如下:
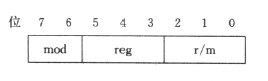
由于 8086/8088 指令中必然有一个操作数为寄存器的值,所以必定会存在寄存器字段。
- mod 位:寻址方式,控制另一个操作数的来源
- mod=11:寄存器,由 r/m 位控制寄存器编号
- mod=00:直接内存,由 r/m 位控制地址的运算方式
- mod=01/10:计算内存,在mod=00的基础上加上了偏移量(字节/字)
- reg 位:指令中所使用寄存器的编号,reg+w → 寄存器
- 操作码字节中的 d 位控制了 reg 所指向的寄存器充当的是什么操作数
- 操作码字节中的 w 位控制了 reg 是取整个字还是一个字节
- r/m 位:寄存器/内存,根据 mod 位取值确定不同的内容
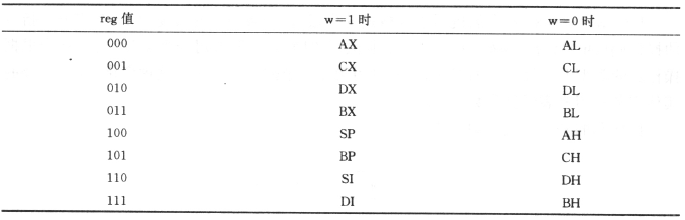
reg 与 r/m(mod=00)时寄存器的取法,需要注意 r/m 与 w 位无关,总是取出整个字

在不同 mod 位的控制下,r/m 位计算地址时的规则(得出的值会用作地址去内存中读出)
段超越字节
当使用寄存器 BP 寻址时,段寄存器默认为 SS;使用 BX、SI、DI 寻址时,默认为 DS。若想主动指定段寄存器,可以使用段超越字节。
段超越字节在操作码字节前,可以在这个字接种指定一个 seg 寄存器,用作后面紧邻指令的段寄存器。
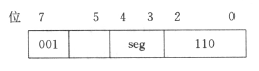
seg:段寄存器
00 → ES 01 → CS
10 → SS 11 → DS
寻址方式
在寻址方式字节中,简单的介绍了指令寻址的写法,对于完整的 8086/8088 指令而言,总共有三类寻址方式:
- 数据相关寻址
- 转移、过程调用寻址
- I/O 指令寻址(在第八章进行介绍)
在进行寻址方式的介绍前,有一个我认为需要区别于 mips 的关键点:
8086/8088 指令大多数都可以直接操作内存,可以直接通过中括号 [] 将括号内的数字/寄存器值/内存值转化为地址,然后直接访问内存取出内存值;而在 mips 中只有 save/load 类指令能操作内存,8086/8088 的自由度要大上不少。注意取偏移时只能使用基址寄存器和变址寄存器(BX、BP;SI、DI)
立即寻址
立即寻址指的是指令所需操作数直接包含在指令代码中,通常是一个常量或常数。
常数为 8 位或 16 位
- 立即寻址方式(立即数)只能出现在源操作数位置,目的操作数可以是寄存器/内存
- 立即数的运算需要注意位宽的匹配,不要出现两个操作数位宽不同的情况
- 立即数表示方式:
- 常数:直接写在指令中
- 常量:先通过伪指令 EQU 定义后,直接在指令中写常量名
VALUE EQU 512 ; 定义常量 VALUE |
寄存器寻址
寄存器寻址指的是指令中所需要的操作数来自某个寄存器,存取操作完全在 CPU 内部进行,执行速度快
可以来自全字寄存器,也可以来自半字寄存器
没有什么好解释的,部分指令虽然不含操作数,但仍可能使用隐含寄存器(PUSHF:PSW 是源寄存器,存入堆栈所在的内存)
直接/寄存器间接/寄存器相对/基址变址寻址
直接寻址是指操作数的偏移地址直接在指令中指出的寻址方式。
寄存器间接寻址指的是操作数的有效地址 EA 不是位于指令中,而是位于且仅位于基址寄存器 BX、BP 或变址寄存器 SI、DI 中。
寄存器相对寻址指的是操作数的有效地址 EA 是一个基址/变址寄存器和指令中指定的位移量的和。
基址变址寻址指的是操作数的有效地址 EA 是基址寄存器+变址寄存器的值
- 直接:用立即数直接在内存中取数
MOV AX, [02000H]
- 寄存器间接:用基址/变址寄存器的值在内存中取数
MOV AX, [BX]
- 寄存器相对:传统
lw/sw,注意可能是 DS 或 SSMOV AX, 10H[SI]
- 基址变址:基址寄存器+变址寄存器
MOV [BP+DI], [BX][SI](指令意为从 BX 和 SI 寄存器中取出值,相加得到内存地址,取出值后存入 BP 和 DI 寄存器值的和所指向的内存空间)
转移指令寻址
标号与过程名
定义数据的变量/符号实质上确定的使它在数据段内的偏移地址,定义代码段/函数可以使用标号和过程名(标签)
- 直接定义了代码段中的偏移值
段内直接寻址
段内直接寻址是要转向指令实际的有效地址是 IP 寄存器和立即数偏移量之和(PC+offset)
JMP SHOUT F1 ; 此处即为段内直接寻址,此处代表 F1 与当前 IP 的位移量 |
- 通常是标号、过程名
- 条件转移指令只能使用 8 位位移量,不需使用 SHORT 等操作符
- JMP 指令携带
NEAR PTR或SHORT操作符则使用 8 位位移量,否则使用 16 位位移量
段内间接寻址
- 通常是寄存器,或寄存器指向的内存值
说白了就是 jr,跳转的寄存器中保存的是相对于当前代码段(CS 寄存器)的偏移值
; p1 作为过程名、ADD1 作为变量名 |
段间寻址
段间寻址的两种方式与段内寻址类似,只不过需要在偏移/目标地址之外给出转移目标的段地址。
- 直接寻址使用的标号或过程名需要具有
FAR属性 - 间接寻址的转移地址不再来自寄存器,而是在内存中的一个双字:
- 高字在高地址、低字在低地址
- 转移后:低字→IP、高字→CS
指令系统
这一节主要介绍 8086/8088 的指令集,接下来的内容会尽量按照课本中给出的顺序记录,同时进行一些内容和示例的精简。
取地址可以使用 OFFSET、SEG 操作符,也可以用 LEA 获取变量的偏移量
根据地址取值可以使用中括号,,取出指向内存单元的内容
数据传送指令
数据传送指令负责把运算过程中所需的数据、地址或立即数传送到寄存器或存储单元中。主要指令有:
MOV、XCHG
MOV DST, SRC ; 将 SRC 的内容转移至 DST |
- 目的操作数不能为立即数
- 源操作数和目的操作数不能同时为内存/段寄存器
- 数据位宽必须保持一致,可以使用操作符进行强制类型转换(BYTE/WORD/DWORD PTR)
XCHG指令不允许出现立即数作为操作数
PUSH、POP
堆栈操作指令,包括四条指令:
PUSH SRC ; 将 SRC 的值存入栈帧 |
- 8086/8088 的栈帧只能以单字为单位存取
- POP 指令不允许使用 CS 寄存器
- 不需手动修改 SP 寄存器的值
LEA、LDS、LES
类似于 load 类指令,以上三个指令从指定地址取出值写入寄存器
LEA reg, src ; 完全是 lw,reg 不能是段寄存器 |
传送指令举例
MOV AX, BL ; AX 16 位,BL 8 位,两者位宽不匹配 |
内存图与传送指令
; 数据定义 |
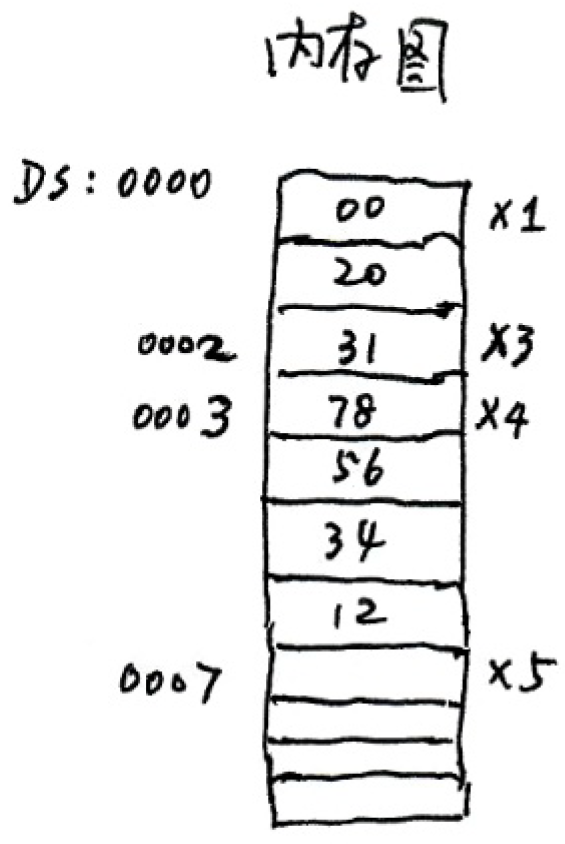
; 移动操作:X4 → X5 (DD → DD) |
; 移动操作: X3 → X5 (DB → DD) |
最后一段的 BX 寄存器一定不能使用 BP 寄存器作为偏移寄存器,因为 [BX] 会以 DS 为基地址,而 [BP] 会以 SS 为基地址,[BP] 会把堆栈已存放的内容覆盖
算术运算指令
部分标志寄存器
- ZF:若运算结果为 0,则 ZF = 1
- SF:等于运算结果的符号位
- CF:运算加法(发生进位)或减法(发生借位)时 CF = 1
- OF:运算操作是否溢出,溢出时 OF = 1
基础算数指令
只介绍基础的二进制数运算指令,下列指令都需要匹配类型,数据结果存储在 dst 中。加减操作中只有自增自减指令不会影响进位标志(CF);乘法也会影响标志位
; 字节、单字运算 |
- 乘除法操作会对寄存器做隐性的类型匹配,但是内存操作数不会判断,需要手动声明!
- 乘除法的 OP 不允许是立即数,可以为内存或寄存器
- 乘法:
src为 8 位:AL × src → AXsrc为 16 位:AX × src → DX:AX
- 除法:
src为 8 位:AX / src → AL ······AHsrc为 16 位:DX:AX / src → AX ······ DX- 需要额外注意溢出:16 位除以 2 位 → 15 位,AL溢出了,程序会产生中断/直接停止
CMP、NEG
CMP 指令虽然会产生标志位,但是实际上实现的是数值相减,只不过结果并未存入 dst 中
NEG opr ; opr 变为 -opr |
CWB、CWD
这两条指令都将 8 位的数据拓展至 16 位,CBW 指令将 AL 符号扩展至 AH;类似的,CWD 指令将 AX 中的符号位直接拓展到 DX 寄存器中(结果非 0 即 0FFFF)
逻辑运算指令
- 逻辑运算指令:AND、OR、XOR、NOT
- 测试指令:TEST
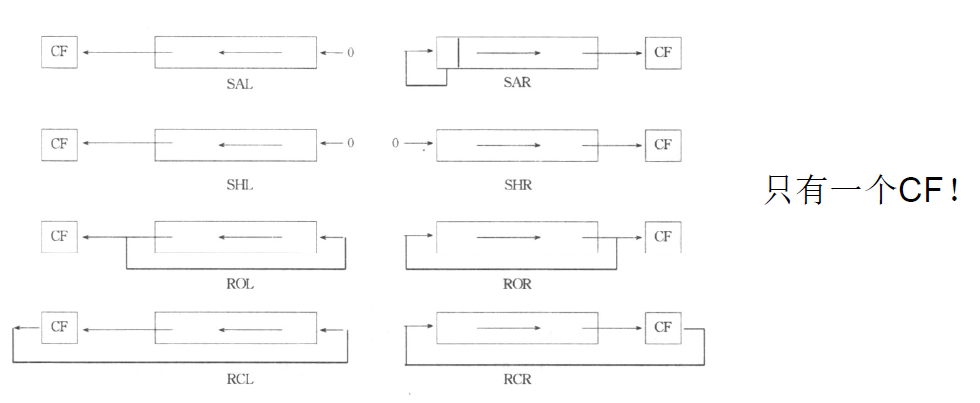
- 移位指令:SHL(SHR)、SAL(SAR)、ROL(ROR)、RCL(RCR)
对逻辑运算指令而言,src 可以是立即数(8/16),使用灵活
- 数字 → ASCII 数字:
OR AL, 030H - 大写字母 → 小写字母:
OR AL, 020H
对移位指令而言,有下图:
控制转移指令
- 条件转移指令:JA、JB、JE
- 无条件转移指令:JMP
- 循环指令:LOOP、LOOPZ、LOOPNZ
- 调用与返回指令:CALL、RET、RETF
条件跳转指令 ABE 比较的是两个无符号数的大小,分别对应 Above、Below 和 Equal
无条件跳转指令相当于 mips 中的 j 指令,需要注意寻址方式:
- 段内直接转移:
JMP NEAR PTR 标号 | JMP SHORT 标号,8 位 - 段内间接转移:
JMP WORD PTR <REG | MEM> - 段间直接转移:
JMP FAR PTR 标号,16 位 - 段间间接转移:
JMP DWORD PTR <REG | MEM>
如果跳标号,就看 SHORT/NEAR/FAR,SHORT 不需要加 PTR
如果跳寄存器,就看有没有取地址,取了就看 WORD/DWORD PTR,没取就直接用
循环指令中,使用的循环计数器均为 CX 寄存器,在执行循环体前先更新计数器,LOOP:CX 不为 0 时转移、JCXZ:CX 为 0 时转移
CALL 指令的执行过程与调用的 dst 相关(四种分类和上面寻址方式一致):
- 段内标号:返回地址偏移值入栈;
IP = IP + D16 - 段内寄存器:返回地址偏移值入栈;
IP = dst - 段外标号:返回地址段值入栈、偏移值入栈;
IP = dst 偏移值;CS = dst 段地址 - 段外寄存器:返回地址段值入栈、偏移值入栈;
IP = EA[15:0];CS=EA[31:16]
对于 RET 指令而言,执行的完全就是 CALL 的逆过程
汇编语言程序格式
本章节介绍 8086/8088 汇编语言中的程序结构、内存布局、指令与伪指令、关键字,以及汇编程序运行过程前/中的调试工作。
分段式程序结构
8086 程序在内存中是以分段形式来组织的,程序在执行时会使用代码段、数据段和堆栈段。它们统合形成完整的汇编程序。
程序组成
在汇编语言中,无论是常数、常量、标号、符号名、指令助记符、伪指令、操作符、参数等,都不区分大小写。
- 在命名规则上,标号和符号名都必须以字母或专用字符(
?,@,-)开头,当常数以A-F开头时,都要在前端补充一个 0,从而与标识符区分
代码段中的内容由主程序和组过程组成,两者都是统一的过程,需要使用伪指令指定。过程必须有一个名字,当只有主程序时,可以省去命名过程。
三段式程序结构
三段式程序包括堆栈段、数据段、代码段三个 segment
- 堆栈段:栈定义、栈区域划分、确定栈顶
- 数据段:纯放数据
- 代码段:指明各个段的声明、主函数中初始化 SS、SP、DS 寄存器、返回 MS-DOS
初始化 SS、SP、DS 寄存器
MOV AX, STACK1 ; |
返回 MS-DOS 的命令提示符
EXIT: MOV AX, 4C00H |
- 向 AH 中放入功能号
4CH,向 AL 中放入返回码00H - 调用 MS-DOS 例程,
4C号功能调用作用是返回命令提示符
整个程序终止处的必备内容:
END MAIN |
END 表示本模块的总结束,后续的内容不会进入汇编,END 后跟着的标号说明本程序的入口是 MAIN
定义程序结构的伪指令
SEGMENT&END
在定义段时需要使用 SEGMENT 和 ENDS 指令。
<NAME> SEGMENT [对齐类型][组合类型][类别名] |
- 段名:由用户喜好定义,无特殊限制
- 对齐类型:相当于 align,确定了段整体的对齐方式,可选项有BYTE(字节)、WORD(字,2B)、PARA(节,16B)、PAGE(页,256B)
- 组合类型:确定段之间的组合方式
- NONE:缺省,本段独立、不指定组合类型
- PUBLIC:将段名相同的小段拼接为一个大段,共用基地址
- COMMON:将段名相同的段覆盖到同一起始地址上
- STACK:说明是堆栈段的一部分,同名段连接为一个连续段
- SS:连续段的首地址
- SP:最大偏移地址
- MEMORY:本段在内存中应定位在所有连接在一起的段的前面
- AT:本段直接以节边界对齐,定位在内存的某个位置
- 类别名:用引号括起来,程序在连接时会把同名的程序放在连续的内存区中,但仍然属于不同的段;优先级低于组合类型
ASSUME
一种设定指令,告诉汇编器各段应该具体是哪些程序段
ASSUME CS:AAA, DS:BBB, SS:CCC |
AAA、BBB、CCC 指的都是某个段的段首地址,用这些地址初始化寄存器(但实际上并没有将地址放进去)
PROC&ENDP
汇编程序中定义的函数(子过程)需要定义为过程。过程通过定义伪指令
PROC和ENDP实现
<NAME> PROC [NEAR|FAR] |
与标号类似,但是定义时没有冒号,NEAR|FAR 定义了过程属性,NEAR 调用时仅压栈 CALL 指令下一条的偏移,FAR 则压栈段地址与偏移;NEAR 过程不修改 RET 指令,FAR 过程将 RET 转化为 RETF,从堆栈弹出两个字充当 IP 和 CS 值
NEAR 程序的 RET 视为段内跳转,FAR 程序的 RET 视为段间返回
ORG
定位伪指令,为某指令、数据指定一个特定的偏移地址,可以使用 ORG 进行限制
DATA1 SEGMENT PARA AT 0B800H ; STRING 在 DATA1 中,从 0B800H 开始 |
END、NAME、TITLE
- END:出现在每个程序、模块的末尾;若带标号则指明了程序开始执行的入口点,被设置为初始的 CS:IP
- NAME:模块名
- TITLE:标题名
数据定义与内存分配
常数和常量
常数和常量指没有任何属性的纯数值,在汇编过后,这些量都会变成纯二进制数
常数类型:二进制数(B)、八进制数(O)、十进制数(D)、十六进制数(H)
常量定义:使用伪指令 EQU
PORT_ADDR EQU 2B5H |
变量与定义
变量的实质是代表存放在内存单元中的数据,这些数据允许程序在运行期间由指令修改。
汇编语言中的变量名代表了存放数据的内存单元的地址,可以通过 OFFSET 和 LEA 指令获取变量的地址
变量的定义使用伪指令 DB、DW、DD、DF、DT 实现(字节、单字、双字、三个字、10Byte 的压缩 BCD) 码
在汇编中,变量名+1永远只会给偏移地址+1,不会+变量大小
$:地址表达式,指向下一个位置DUP:重复操作符?:不预置任何内容- 字符串表达式:用引号、逗号分配字符串,初始化为字符的 ASCII 码
- DD、DW 不允许两个以上字符的字符串作为参数
- 地址表达式
repeat_count DUP (operand, ...,operand) |
表达式与操作符
表达式
表达式是操作数的一种,它由常量、变量、寄存器、标号和一些操作符相组合,程序在汇编时会按照一定的优先顺序进行计算得出数值或地址
算术操作符
常用的算术操作符有 +, -, *, /, MOD,MOD 是求余数的双目操作符;算术操作的数和结果都必须是整数,除法运算的结果只保留商
逻辑运算符
主要有 AND、OR、XOR、NOT 四个,逻辑操作符是按位操作符,只能用于数字表达式中,需要注意数字的类型匹配
关系操作符
关系操作符对两个表达式进行比较,常数 or 同一段的两个内存地址,结果为真时=0FFFFH,结果为假时=0;主要的几个关系操作符有:EQ、NE、LT、LE、GT、GE,含义见首字母缩写
数值回送操作符
TYPE、LENGTH、SIZE
- TYPE 指令用于求出变量、数组的类型,其返回值如下:
| 变量或标号 | 属性 | 类型值 |
|---|---|---|
| DB 类型变量 | BYTE | 1 |
| DW 类型变量 | WORD | 2 |
| DD 类型变量 | DWORD | 4 |
| 段内标号、过程名 | NEAR | -1 |
| 段间标号、过程名 | FAR | -2 |
使用时可以充当其他指令的操作数,例如 MOV AL, TYPE VAR
- LENGTH 指令用于求出变量名的单元数:使用 DUP 则是 DUP 的次数、未使用则是 1
- SIZE 指令用于求出分配给变量名的字节数
OFFSET、SEG
- OFFSET 指令计算变量名、标号和过程名的偏移值地址
- SEG 指令计算其所处的段地址
属性操作符
PTR、段操作符、SHORT、THIS、HIGH、LOW 六种操作符
PTR的作用是强制说明或转换存储单元的类型为指定的种类,修改视为一次性修改THIS为某个变量指定一个类型;为一个标号/过程名指定一种转移距离- 段操作符就是段超越的表示方式
SHORT操作符说明JMP的跳转地址为 8 位偏移量,而不再是 16 位(范围为IP-128 \~ IP+128字节)HIGH和LOW操作符为字节分离操作符,HIGH说明取出变量的高字节、LOW同理- 注意字节分离操作符不能应用于内存操作数(取它们的字节可以使用
BYTE PTR)
- 注意字节分离操作符不能应用于内存操作数(取它们的字节可以使用
X1 EQU THIS BYTE ; X1 视为 BYTE 类型的量 |
汇编、连接和运行
接下来的部分是汇编程序设计,主要关注 8086/8088 程序的实际操作
对 x86 汇编语言进行编译需要使用一些底层开发环境,我们采用了 Microsoft 的 MASM,它能够为程序的书写、检查、编译、调试等操作做出相关支持,是最常见的编译环境之一。
初始化开发环境的操作可以参考第一次上机实验的实验报告。MASM 环境提供了多种内置程序负责对汇编文件进行处理,下面将按序介绍。
asm 编译(含 LST 文件) → obj 链接(含 MAP 文件) → exe 执行
编译
masm <file.asm> |
直接执行汇编操作。可以通过 /l 参数生成列表文件 LST,它可以帮助我们分析指令和数据所占的地址位置以及指令的机器码,也可以获取文件中的段消息与符号量信息:
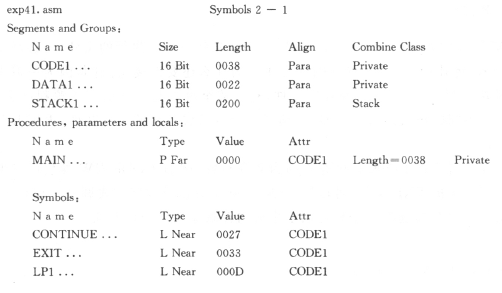
链接
link <file> |
直接进行链接操作,可以通过 /MAP 参数生成内存映像文件:MAP 文件。MAP 文件主要对段的地址分配作了说明,标定了程序段在内存中的首尾位置,同时也会提示程序的入口地址。
调试与DEBUG
汇编程序的 debug 可以通过在开发环境中运行 debug.exe 实现。主要的命令有以下几个,一些具体的用法仍可以在实验报告中读到。
-t:单步执行
-g <addr>:执行到 addr 指向的指令地址
-u <addr>:查看以 addr 为首的一段指令段内容
-d <addr>:查看以 addr 为首的一段内存段/堆栈段内容
-r <reg>:修改某寄存器的内容;不加 reg 会查看当前执行状态
-a <addr>:修改 addr 偏移处指令的内容
-e <addr>:修改 addr 偏移处内存单元的内容
-q:退出 debug



