
BUAA-FPGA多核并行计算-Exp1
本系列是北航计算机学院于 2024 年春季学期开设的一般专业课《FPGA多核并行计算》课程的实验报告记录,由于学习过程中掌握并不牢靠,如有错误请读者不吝赐教!
在线实验平台使用及初识PYNQ
代码及相关数据文件上传在 Github 仓库中。
实验分析
硬件滤波器Overlay的制作
- 打开Vivado,创建新工程,工程类型为
RTL Project,板卡型号选择pynq-z2 - 在左侧菜单中,选择
IP INTEGRATOR下的Create Block Design项,创建模组设计并在模组中添加ZYNQ7 Processing System、FIR Compiler和AXI Direct Memory Access这三个模块 - 完成模块添加后,对模块进行修改
- 双击
ZYNQ7 Processing System模块,做如下修改:- 选择
PS-PL Configuration页,勾选HP Slave AXI Interface页的S AXI HP0 interface,启用PS端的AXI协议数据传输接口
- 选择
- 双击
FIR Compiler滤波器模块,做如下修改:- 修改其中的系数向量(系数向量详见后部软件实现滤波器部分)。
- 在
Channel Specification页修改采样频率与时钟频率均为100MHz。 - 在
Implementation页面修改Output Rounding Mode为Non Symmetric Rounding Up,修改输入输出数据位宽为32位。 - 在
Interface页面设置TLAST为Packet Framing,并勾选Output TREADY以输出TREADY信号。
- 双击
AXI Direct Memory Access模块,做如下修改:- 取消勾选
Enable Scatter Gather Engine,此处不需要非连续地址的数据传输,故可关闭SG模式 Width of Buffer Length Register设置为23位
- 取消勾选
- 双击
- 点击
Run Block Automation进行自动添加附加模块。 - 将
FIR Compiler的M_AXIS_DATA端口与AXI Direct Memory Access的S_AXIS_S2MM端口相连,用于将DMA模块的数据传输给滤波器模块。 - 将
FIR Compiler的S_AXIS_DATA端口与AXI Direct Memory Access的M_AXIS_MM2S端口相连,用于将滤波器模块的输出结果回传给DMA模块。 - 在
Block Properties中对AXI Direct Memory Access模块进行改名,此处修改为fir_dma,并将FIR Compiler模块改名为fir,同时选中fir和fir_dma模块,点击右键,选择Create Hieracty,创建层次,并将其命名为filter - 点击
Run Connection Automation进行自动连线,连线过程中勾选All Automation(注:此处的自动连线需要执行两次)。 - 切换至
Sources分页,选择当前的Design Sources,点击右键,选择菜单中的Create HDL Wrapper,生成顶层包装(将模块设计包装起来) - 选择
Generate Bitstream,生成Overlay所需要的比特流文件,注意,在点选之后,综合(Synthesis)和执行(implementation)均会在后台运行,此刻可查看界面右上角是否有流程未完成,或打开Log界面查看当前任务所输出的日志。 - 分别选择
File菜单下的Export中的Export Bitstream File、Export Block Design导出比特流文件.bit和模块设计的tcl约束文件,并在工程名.srcs/sources_1/bd/design_1/hw_handoff文件夹下找到.hwh的硬件描述文件,将此三个文件改为同一文件名存放至同一工作目录下,即可作为PYNQ平台的Overlay进行使用。
说明:
ZYNQ7 Processing System为ZYNQ7系列板卡(如xc7z020、xc7z100,PYNQ-Z2板卡使用的是xc7z020)所设计的PS侧资源的抽象模块。FIR Compiler为Xilinx所内置的滤波器IP核(IP核为预先设计好的电路功能模块),修改其中的系数向量(Coefficient Vector),即可实现所需要的滤波功能。TLAST选择为Packet Framing时,每个数据帧完成后将传出信号,数据将按包接收TREADY勾选时将输出TREADY信号,其与TVALID信号实现了握手
本图为实现元件连接后的示意图,最左侧时组合后的filter,右侧是zynq模块,图示元件共同构成了硬件滤波器。
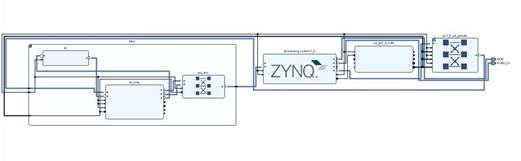
本图是在仿真综合后,Vivado得到的设备仿真图。

软件滤波器的构建
- 首先需要构建原始信号
- 使用SciPy中的
lfilter方法进行对输入信号进行滤波,并记录软件滤波器执行耗时;滤波器系数向量可通过http://t-filter.engineerjs.com/生成,通过滤波,可将高于5MHz的信号过滤掉。
硬件滤波器Overlay的使用
- 将生成的Overlay(.bit,.hwh,.tcl三个文件)拷贝到工作目录下
- 使用PYNQ的xlnk类,申请输入输出缓冲区,并使用dma对输入数据和输出数据进行处理
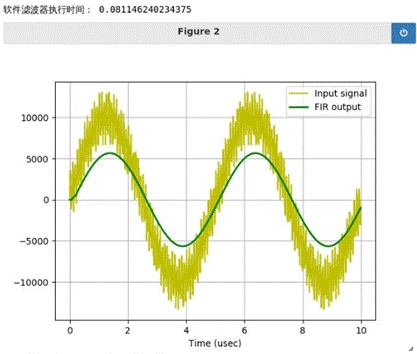
下图是执行结束后的结果:

实验思考
- 计算回答为何AXI Direct Memory Access 模块的Width of Buffer Length Register 设置为23位?
DMA模块中的Buffer Length Register 用于控制单次传输操作中可以处理的最大数据量。位宽为23位,说明DMA能够一次性传输8 MB数据。这个值是基于DMA的设计和应用需求而决定的。过小的Buffer难以即时传递采样获取的信息,过大的Buffer会提升内存管理的复杂性。
- 参考Python Overlay API的文档,通过对Overlay类进行封装,实现滤波过程的驱动编写。
""" |
- 请思考或建立新工程尝试,若省略2-7的Create Hieracty 步骤,则可通过什么其他方式对DMA模块进行访问?
若省略2-7的Create Hieracty 步骤,也就是不创建filter层次,可以选择在Python文件中直接调用以下语句对 DMA 模块进行访问。
dma = overlay.fir_dma # 加载滤波器的DMA |
实验总结
问题总结
- 在进行实验步骤4.2时,我的notebook发生了如下报错:

回查后发现是Vivado中忘记对 DMA 模块做出如下修改:
1. 取消勾选Enable Scatter Gather Engine,此处不需要非连续地址的数据传输,故可关闭SG模式 |
修改后重新综合,覆盖实验文件后出现正常现象。但尚未研究清楚其中的原因。
实验建议
本次实验是第一次FPGA的上机实验,对我而言,之前尚未接触过pynq和相关的知识。在这次上机时,能够感觉出实验指导书的步骤详尽,引导性强,但是整体实验后由于理论和基础知识不足,不能理解实验操作如何、为何能够得到实验现象。希望实验能够增加一些前期的讲解,理解运用上可能会更有裨益。
实验收获
通过本次实验,我初步认识了FPGA的设计流程和课程中“并行计算”的意义,硬件中实现的滤波器效率要远高于软件模拟出的元件,再次佐证了FPGA在实现计算加速的优越性。
实验1:在线实验平台使用及初识PYNQ
- 实验文档见 Github 仓库



