
BUAA-CompilePrincipal-Chapter4
编译原理笔记
第 08 讲 ~ 第 10 讲:错误处理、语法制导翻译技术、语义分析和代码生成
第 08 讲 错误处理
错误的定义与分类
编译器在面对错误的源程序时需要进行语法、语义上的处理,发现成分的错误。一般错误分为两类:语法错误和语义错误
- 语法错误:不符合语法规则(上下文无关的);简单来说就是看上去就不是人话
- 语义错误:不符合语义规则、超越系统限制
- 语义规则:
- 标识符先定义后引用
- 标识符引用满足作用域规定
- 函数调用时形参、实参类型与数量匹配
- 参与运算的操作数类型匹配
- 数组等下标不允许越界
- 系统限制:
- 数值溢出
- 符号表、静态存储区溢出
- 动态存储分配区域溢出
错误的诊察与报告
对错误的勘察大致可以分为三部分:语法规则检查、语义规则检查、溢出错误检查,分别进行在语法分析、语义分析和程序运行中。
错误报告需要判断出错的位置和错误性质,位置指的就是行号或 Token 的计数器;错误性质要根据进行的错误处理具体判断
错误处理技术
发现错误后并报告后,需要对错误进行处理,使得编译能继续执行。
- 错误改正:对于语法错误可以根据文法进行错误改正,但由于文法的复杂性很难实现
- 错误局部化处理:将错误产生的影响限制在一个范围内,避免错误扩散对其他部分造成进一步影响
下面介绍错误局部化处理的几个步骤:
- 当诊察到错误时,先暂停分析,跳过词法分析中出现的不合法单词、语法分析中当前的语法成分,向下分析
- 找到对应的合法后继符号(语法成分的后继符号)和停止符号,控制错误影响的范围
第 09 讲 语法制导翻译技术
翻译文法
- 动作符号:以
@开头,代表执行某个功能的符号,@print('a')可以代表输出字符a,输出字符串也可以直接写成@a - 翻译文法:翻译文法是上下文无关文法,在翻译文法中,终结符号集合由输入符号和动作符号组成。
- 活动序列:由翻译文法确定的语言中的符号串
- 输入序列:活动序列中删掉所有动作符号后得到的序列(就是输入符号)
- 动作序列:同理,删掉所有输入符号后得到的序列
如果一个翻译文法的所有动作符号都是输出符号串,那么这个翻译文法又叫符号串翻译文法;更普遍的来说,动作可能是执行某些子程序,实现拓展功能等
语法制导翻译
- 语法制导翻译:根据输入文法获得翻译该符号串的动作序列,并执行动作序列里的所有动作的过程
对于符号串翻译文法而言,输出序列和动作符号序列的意义是相同的,以后缀表达式为例,动作序列 @a@b@c@*@+ 和输出序列 abc*+ 在意义上是等价的,都可以认为是输入 a+b*c 的翻译
在尝试编写某个已有文法的符号串翻译文法时,需要根据输出序列和动作序列的要求,来合理安排动作符号在文法中的位置,借此来让动作序列效果等价于输出序列
属性翻译文法
引入属性翻译文法,需要向符号引入值(属性)的概念。在翻译文法的所有终结符、非终结符和动作符号中,都具有值的概念,通常而言有自下向上传播的综合属性和自上向下传播的继承属性。在引入这两种属性后,我们就可以对属性翻译文法进行定义。
属性翻译文法是一个满足下列约束条件的翻译文法:
- 终结符、非终结符和动作符号都带有属性,且属性有对应的值域
- 非终结符和动作符号可以具有综合属性和继承属性
- 起始符号的继承属性和终结符号的综合属性都具有初始值(前者预定义,后者源自输入)
- 继承属性:
- 产生式右端的继承属性来自于该产生式中左侧的其他符号
- 如在产生式左端,则寻找一个自身在右端的产生式,套上一条
- 符号的继承属性表示为 $A_{\downarrow p}$
- 综合属性:
- 产生式左端的综合属性来自于右端符号的运算
- 动作符号的综合属性来自于其他属性值
- 符号的总和属性表示为 $a_{\uparrow q}$
- 对于文法中的属性计算,也需要形成对应的属性求值规则
一个属性翻译文法的实例如下:

包含属性求值规则的文法,这里的 $@ ANSWER$ 是一个动作,意为执行 $ANSWER$ 函数,参数为 $r$
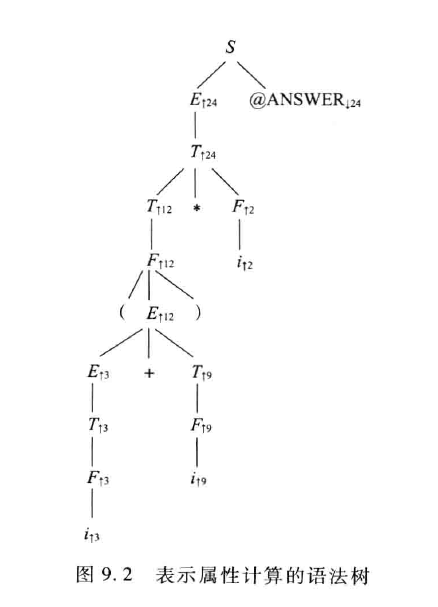
示例的属性计算语法树,输入串为 $(i_{\uparrow 3}+i_{\uparrow 9})*i_{\uparrow 2}$


