
BUAA-OS-2023-Lab2-Report
BUAA-OS-2023-Lab2-Report
Thinking 2.1
虚拟地址在系统中的使用
根据指导书说明:
而在实际程序中,访存、跳转等指令以及用于取指的PC寄存器中的访存地址都是虚拟地址。 我们编写的C程序中也经常通过对指针解引用来进行访存,其中指针的值也会被视为虚拟地址,经过编译后生成相应的访存指令。
故在编写的C程序中指针存储的地址和汇编程序中lw和sw使用的值都是虚拟地址。
Thinking 2.2
链表宏与对应的链表结构
- 从可重用性的角度,阐述用宏来实现链表的好处。
使用宏进行链表实现,一方面能够规范系统内所有链表的存在形式,达成结构上的统一,易于编码与链表维护; 链表宏中大部分传入的参数并不是链表项整体,而是不包含链表具体存放信息的一个结构体,这个结构体只负责管理链表指针。 我们利用宏对这个结构体进行处理,一方面统一链表操作,不限制可以使用链表的结构类型;另一方面能够降低链表指针与链表内容间不必要的耦合性,维护数据安全;使用预设结构还能保证链表结构的正确性。 查阅资料后得知,除了重用性角度外,使用宏定义还意味着放置在queue.h内的所有宏都是完整的,不需要编译为库文件
- 分析单向链表、循环链表和实验中使用的双向链表在插入与删除操作上的性能差异。
头文件
queue.h为C语言中的链表提供了更加标准规范的编程接口。如今的版本多为伯克利加州大学1994年8月的8.5版本。 每种结构都支持基本的操作:
- 在链表头插入节点
- 在任意的节点后插入节点
- 移除链表头后的节点
- 前向迭代遍历链表
我们打开对应的文件/usr/include/sys/queue.h,可以发现其中不仅仅包含了我们使用的双向链表LIST、待分析的单向链表SLIST和循环链表CIRCLEQ,还有两个有尾链表结构TAILQ和SIMPLEQ(双向有尾/单向有尾),这5个数据结构共同构成了LINUX的链表宏定义(为节省空间,下文只拿出所需的定义进行解释,其他定义便不再详述,完整定义会贴在全文最后)
- 单向链表
SLIST:
单向链表(Singly-linked List)在结构上较为简单,链表项只包含一个指向下一个元素的指针 
#defineSLIST_ENTRY(type)\ |
- 插入操作:
- 链表中插入(已知前驱元素指针)需要修改被插入项
slistelm和自身elm的指针,即需要两条指令; - 插入第一个元素需要修改自身
elm的指针指向原有的第一项,同时还需要修改链表头项的slh_first指向自身,也需要两条指令
- 链表中插入(已知前驱元素指针)需要修改被插入项
- 删除操作:
- 链表中删除(无前驱元素指针)需要判断是否前驱元素为链表第一个元素,是则归入第二类,不是则需要从头部开始遍历得到前驱元素,并修改前驱指针指向自身的后继元素,需要2n+2条指令
- 删除第一个元素只需要修改链表头指向的链表项即可,即一条指令
#defineSLIST_INSERT_AFTER(slistelm, elm, field) do {\ |
- 循环链表
CIRCLEQ:
LINUX宏定义下的循环链表只存在双向循环链表CIRCLEQ一种,它是Circular queue的简写 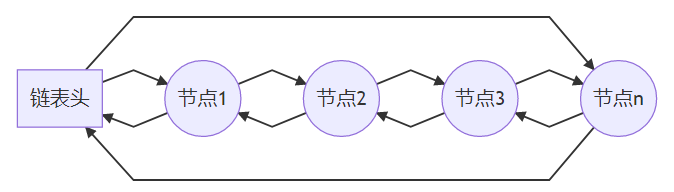 由于循环链表有头有尾,故链表头项包含两个指针:
由于循环链表有头有尾,故链表头项包含两个指针:cqe_first和cqe_last
同时每个链表项与双向无尾链表LIST结构稍有不同,它有两个指向链表项的指针:cqe_next和cqe_prev
由于可以提供双向+头尾指针,所以循环链表可以有多种插入方式:
在进行插入操作时,需要考虑到是否仅含一个元素的情况,这时需要对链表头项进行修改,与其他情况稍有不同(以INSERT_HEAD为例)
if ((head)->cqh_last == (void *)(head)) \ |
- 双向链表
LIST:
然后就是我们在实验中使用到的双向链表LIST,它与其他内置链表宏的最大区别就是链表项:LIST含有一个指针和一个二重指针
也因为其能够进行双向操作,插入的方法也有多种
这里需要注意执行向后插入的INSERT_AFTER和INSERT_HEAD都需要判断是否为最后一个元素,决定是否需要调整后继元素的le_prev指针 分析后可以看出,
- 单项链表
SLIST执行插入的效率最高,但是删除时需要进行遍历操作以防止后续链表元素丢失,性能较差; - 循环链表
CIRCLEQ执行插入的效率稍低于单项链表,删除效率要高于单向链表,但需要进行分支判断,也为常数级 - 双向链表
LIST插入效率与循环链表类似,删除效率略高于循环链表
Thinking 2.3
查看pmap.h得知Page_list结构调用了LIST_HEAD()宏定义
LIST_HEAD(Page_list, Page); |
同时还定义了Page结构体和Page_LIST_entry_t:
struct Page { |
于是可以得出完整结构:
struct Page_list { |
故选择C选项
Thinking 2.4
- 请阅读上面有关R3000-TLB 的描述,从虚拟内存的实现角度,阐述ASID 的必要性。
ASID,Address Space IDentifier 用于区分不同的地址空间,同一虚拟地址通常在不同的地址空间中映射到不同的物理地址。
也就是说,ASID用来标记当前虚拟地址所归属的程序号,如果访问的是其他程序的虚拟地址,通常会指向一个错误的物理地址。因此需要确保访问的请求来自特定的程序,于是采用了ASID作为保险,确定虚拟地址请求的来源。
- 请阅读《IDT R30xx Family Software Reference Manual》的Chapter 6,结合ASID段的位数,说明R3000 中可容纳不同的地址空间的最大数量。
ASID段占用的数据位为[11, 6],共6位,则意味着R3000中可容纳不同的地址空间的最大数量为64。
Thinking 2.5
- tlb_invalidate 和tlb_out 的调用关系?
打开kern/pmap.c文件并找到tlb_invalidate函数定义如下:
void tlb_invalidate(u_int asid, u_long va) { |
易知C语言函数tlb_invalidate调用了汇编函数tlb_out
- 请用一句话概括tlb_invalidate 的作用。
删除在序号为ASID的程序规划的虚拟空间中,虚拟地址va所在页在TLB中的页表项
- 逐行解释tlb_out 中的汇编代码。
tlb_out代码如下
LEAF(tlb_out) |
Thinking 2.6
- 简单了解并叙述X86 体系结构中的内存管理机制,比较X86 和MIPS 在内存管理上的区别。
在x86架构中内存被分为三种形式,分别是逻辑地址(Logical Address),线性地址(Linear Address)和物理地址(Physical Address)。其中分段可以将逻辑地址转换为线性地址,而分页可以将线性地址转换为物理地址。 并且x86允许存在不分页的情况,但不允许程序不分段 MIPS 与 X86 的 TLB 差别 其在于对 TLB 不命中时的处理上: MIPS 会触发TLB Refill 异常,内核的 tlb_refill_handler 会以 pgd_current 为当前进程的 PGD 基址,索引获得转换失败的虚址对应的 PTE,并将其填入 TLB,完了CPU 把刚刚转换失败的虚地址再走一下 TLB 就OK了。 而 X86 在 TLB 不命中时,是由硬件 MMU 以 CR3 为当前进程的 PGD 基址,索引获得 PFN 后,直接输出 PA。同时 MMU 会填充 TLB 以加快下次转换的速度。





