
BUAA-OS-Probe-Lab4
Lab4 - 系统调用与进程创建
Lab4 中主要涉及到以下内容:
- 系统调用
syscall的流程 - 进程间通信机制:ipc
- 用户进程的创建方式:
fork函数 - 写时复制 COW 与页写入异常
首先需要明确一件事,这篇文里说的大部分和汇编相关的内容估计都不会考,只是用来全面理解每一步的具体作用而已。所以写了一坨好多都是没营养的东西,请善用目录! 其实最不好理解的部分是在汇编代码和C代码之间切换的部分,可能一些宏定义、编译器的一些操作就会漏掉很多细节。 所以,时不时用用
make objdump吧!努力成为 buaa-os 领域大神(?
系统调用
在计算机组成原理实验 P7 与 Lab3 中,我们大致已经能够理清异常的原因、怎样产生与处理的方式了,但在 MOS 之前提到的异常大多不能由用户主动触发(时钟中断、TLB MISS 等),接下来我们就要深入了解一种特殊的、可以由用户主动发起的异常:系统调用 syscall
- 异常发生的原因:出现某些不符合操作规范的指令、外部中断、syscall 指令
- 产生地点(硬件):指令流水至(M级)时 CP0 协处理器分析异常,修改 SR、Cause 等寄存器,使得当前 PC 跳转至异常处理程序入口(
0x80000000) - 异常处理(软件):异常处理程序对 CP0 记录的信息进行分析,选择对应的 handler 函数并跳转;对应 handler 处理结束后通过 ret_from_exception 汇编函数返回 EPC,程序继续执行
我们想要使用 syscall 指令,为的就是进入内核态,让操作系统为用户执行某些任务,这些任务出于安全等考虑,只有内核才能完成,所以在调用 syscall 时,就不可避免地要进行 CPU 状态的切换(标记于 SR 寄存器的 KUc 位中)
系统调用在干啥()
在详细了解系统调用前,还有必要再补充一下进程运行时的虚拟空间知识(可以补充在Lab3中?) 每个进程,都有相同的虚拟地址划分方式,并按照 mmu.h 文件中所示进行排布。每个进程都具有一张这样的表。同时每个进程的 kseg0、kseg1 段也都存放(或者说映射)着内核相关的数据结构,存在于所有进程的虚拟空间中,相当于被所有进程只读共享。所以为了方便使用,它们被整体映射到物理地址的固定区域;对于 kuseg 段,用户的页表和虚拟地址相结合,会指向物理内存中的某些空间,不同进程可能对物理空间进行共享。 执行系统调用,汇编层面上就是从 kuseg 段的汇编指令跳转至 kseg0 段,(进入内核态)并执行特定序列(系统调用函数),最后返回用户态 EPC 。C层面上就是用户态函数和内核态的系统调用函数之间的调用跳转。
系统调用过程概览
我觉得 os 学的就是一个全局观,先把需求和路线理清了,细节咱们随后再细说(
- 用户提出请求:
syscall_函数
在 MOS 中,操作系统为用户准备了一系列可以在用户态调用的函数: syscall_* 系列函数,他们每个函数都对应一个可以通过系统调用完成的任务,用户通过调用这些函数,向操作系统传达信息:我要使用系统调用完成某个功能
- 进入内核态:汇编函数
msyscall
在刚提到的 syscall_* 函数中,存在一个 msyscall 函数,在这个汇编写成的 msyscall 中,才出现了真正的 syscall 汇编指令,也就是在这里正式地进入了内核态,准备使用异常处理程序解决 syscall
- 用户态保存:
exc_gen_entry
在异常处理程序中,调用 SAVE_ALL 保存当前现场为内核栈中的 trapframe ,并将当前使用栈转换为内核栈。
- 接收请求并分类:
handle_sys
通过异常处理程序判断为系统调用后,转入 handler 这个函数创建了一个size = TFSIZE + 8 大小的栈帧,8byte 为了保存参数 *tf(函数开始后会写回 a0 寄存器)
- 参数预处理调用处理函数:
do_syscall
在这个函数中,我们通过分析用户传入的信息(syscall_* 的类型和用户现场)来响应系统调用。 分析主要凭借 tf->regs[29] 获取用户 trapframe 状态,通过sp访问内核栈获取参数等
- 响应完毕,返回用户态:
ret_from_exception
在从 do_syscall 跳出并执行完对应处理函数,并返回至 handle_sys 后,最后会和其他异常一样,执行 ret_from_exception,还原现场,返回用户态,整个系统调用的过程结束 至此,整个执行流程可以总结为这张图片: 
发起系统调用 - syscall_*
上面提到,可由用户调用、距离内核态最近的函数就是这一系列 syscall_* 函数了。它们作为用户可调用的函数,位于 user/lib/syscall_lib.c 文件中,现在来看看它们的具体内容:
// 为节省空间仅保留了部分函数,反正差不多里面所有函数都长这样() |
可以看到,它们都只调用了不同参数的 msyscall 函数,然后早早跑路(x)。这里还需要注意,syscall_putchar、syscall_yield、syscall_panic 这几个函数没有以”return“的方式调用 msyscall ,因为他们不是 void 的,就是 noreturn 的,憋憋 可以发现每个不同的函数,第一个参数一定不同,并且都代表了这个函数。也就是说, msyscall 通过接收这系列函数传入的第一个参数,决定最后响应的内核函数是谁,而后续的参数充当信息,用于辅助处理。
转入内核态 - msyscall - Exercise 4.1
这个在用户态执行的最后一个函数(但用户编程过程中实际上不用),位于 user/lib/syscall_wrap.S 中,这个函数很简单:
#include <asm/asm.h> |
这个函数实际上充当了用户态、内核态的转接口:执行 syscall 进入内核态,从调用返回后执行 jr ra ,十分简洁,分工明确 我们可能注意到了不同的 msyscall 调用可能有不同的参数数量,他们都被保存在堆栈中为函数创造的 stack frame 空间中,与 sp 相邻。 下一步,内核就会接收到由硬件产生的 8 号异常,通过处在 kern/entry.S 的异常分发程序 exc_gen_entry 跳转到 handler 函数: do_syscall
分发系统调用 - do_syscall
首先需要注意,在跳转至 do_syscall 前,我们在异常分发程序中向内核栈(SAVE_ALL)压入了用户态 trapframe 的信息。随后又通过 move 指令把 a0 寄存器复制成了 trapframe 的地址(SAVE_ALL 中 move sp 的值) 所以 do_syscall 在调用时就会自动地带有一个参数,它就是存放在 a0 寄存器中的用户态 trackframe 指针(为什么是指针?因为传入的 sp 的值实际上指向了存放 tf 的地址)
void do_syscall(struct Trapframe *tf) { |
用户栈与内核栈
- 这里 sysno 取自 a0 寄存器,那前面说的 tf 地址保存在 a0 寄存器又是什么呢,不会互相覆盖吗?
- 首先结论很明显,不会。这里的两个 a0 指的不是同样的东西
首先我们需要明确一点:当进程运行在用户态时,使用的是用户栈,栈指针也指向用户栈;每当进程通过异常从用户态切换到内核态时,handler 会执行汇编函数 SAVE_ALL。 它的具体作用是把用户态的所有寄存器都保存到一个 trapframe 中,同时这个 tf 会被放置在内核栈中,同时还会切换当前使用的栈空间为内核栈。并且切换时内核栈总是空的。内核栈此时就保存了进程在进入内核态前的相关信息。重回到用户态时,再通过 ret_from_exception 中的 RESTORE_SOME 将内核栈中保存的信息恢复,再切回用户栈。 因为内核栈在切换后总是空的,每次又只会传入一个 trapframe ,所以这个 trapframe 实际上每次都占用的是 KSTACKTOP 向下的一个 sizeof(trapframe) 大小的空间 所以会出现这样的空间图:
- stackframe:调用函数时创建,保存函数的参数、临时变量与相关跳转指针
- trapframe:陷入内核时使用
SAVE_ALL创建,保存用户态寄存器
 新的内核栈 sp 指向 trapframe,旧的用户栈 sp 指向 arg0
新的内核栈 sp 指向 trapframe,旧的用户栈 sp 指向 arg0
- 使用当前(内核栈)的 sp,能访问到 trapframe 的信息;使用 tf 中 sp (用户栈)的信息,能访问到最近的 stackframe 的信息
回到我们的 sysno,它是 msyscall 的第一个参数(用户态函数),也就是在分发异常调用 SAVE_ALL 时保存的 a0 寄存器,来源是用户态,所以要从用户态的 tf 里取 a0 寄存器(tf->regs[4]);而参数 *tf 是保存在了调用 do_syscall 时的内核态 a0 中,并不干扰
- 后面的 arg4 类似,同样来源于用户态,但由于寄存器内没有保存,所以不能直接从 tf 里取得,需要通过用户栈指针回到 stackframe 中获取(tf->regs[29] + 16)
栈帧 - stack frame
这里是实际在网站里的教程里有讲过了,当时没有仔细理解,感觉还是再说说吧。 昨天有同学问我说为啥NESTED(handler_sys, TFSIZE + 8, 0)提示编译器共有 TFSIZE + 8 字节的栈帧,但是 ra 却只移动了 8Byte。然后我就发现,我确实没理解栈帧。。 存疑:栈帧在C语言函数中自动创建,汇编函数中需要手动创建 以下内容根据 R3000 手册筛选,但不能保证正确性,为了讨论,这里就只涉及到非叶函数,也就是一般函数的栈情况
- 栈帧 stackframe 创建于刚刚进入函数时:编译器会令 sp 指针向下移动一定空间,并使得这段空间成为该函数栈帧(大小由编译器通过函数变量、子函数参数、临时变量等指标确定;需要注意双字对齐,所以在没对齐时需要补充空白的单字(称作pad))
- 随即,编译器调用 sw 指令,把 a0 - a3 寄存器中存放的本函数前四个参数填充到紧邻本栈帧的上方的空间里,不够四个就有几个补几个
- 栈内高地址存放函数的临时变量等,低地址预留本函数可能调用的子函数的参数的空间,这部分空间在进入子函数时又会成为子函数第二步填充参数的地方
那回来说这个 handler_sys,它通过NESTED宏中的.frame向编译器声明自己需要 TFSIZE+8 字节的栈帧,但是自己却只移动了 8 字节的 sp。 我感觉是因为 TFSIZE 实际上是上面调用 SAVE_ALL 时移动的一个 TFSIZE,这里为了避免覆盖掉就把它看成了栈的一部分(小孩子瞎猜的)。真正有用的是那8个字节:4字节的arg1和4字节的pad,而arg1又是在进入子函数do_syscall内,才从 a0 寄存器中填充的
系统调用函数
了解完系统调用的流程后,下一步就是填写具体用于处理系统调用的函数了,可能会把能写的都写一下,建议是跳着看。
获取进程块 - envid2env -Exercise 4.3
首先是 envid2env 这个函数,它用来获取id对应的进程控制块。虽然它不是系统调用的一部分,但在进行交互、系统调用时,经常使用
int envid2env(u_int envid, struct Env **penv, int checkperm) { |
函数本身没什么问题,但要注意 envid == 0 时必须提前退出函数,否则会一直运行到最后,返回 envs 内的第一个进程控制块
- 当 checkperm == 0 时,不需处理进程块与当前进程之间的关系,反之则需要确保调用本函数的进程是被调用者的直接父亲或本身,否则返回错误。值得一提的是,除了在进行 ipc 通讯的过程外,所有 syscall 函数都需要令 checkperm != 0(传信息不用限定在父子进程中)
强制进行进程切换 - sys_yield - Exercise 4.7
具体而言就是调用一次 schedule 函数,使得运行的进程交出 CPU 时间片,记得 yield 别传 0()
void __attribute__((noreturn)) sys_yield(void) { |
需要注意这里函数 noreturn ,也就是说会直接开始运行下一个进程块
指定进程建立 va2pa 的映射 - sys_mem_alloc - Exercise 4.4
- 函数作用:为指定进程的 va 申请一个物理页面并形成映射
- 类似于跨进程的 page_insert
- 操作:
- 确认 va 和 env 的合法性,如有错误则直接返回错误值
- 申请一个物理页,调用 page_insert 生成映射
int sys_mem_alloc(u_int envid, u_int va, u_int perm) { |
乍一看这不就是一个 page_insert 吗,仔细一看确实。但是用户态的 page_insert 无法帮其他进程申请一个映射,因为根本看不到其他进程的进程块,所以原则上需要看得见所有东西的内核态来帮忙
在不同进程间形成共同的映射 - sys_mem_map - Exercise 4.5
- 函数作用:说白了就是把 src 进程 va 所在的物理页,在 dst 进程中找了指定位置形成了映射(insert)
- 操作:
- 检验传入的两个 va 合法性
- 获取 srcid 和 dstid 的进程控制块
- page_lookup 获得 srcva 在 srcid 中映射的物理页
- page_insert 让物理页在 dstid 中也形成一个映射
int sys_mem_map(u_int srcid, u_int srcva, u_int dstid, u_int dstva, u_int perm) { |
解除指定进程的映射 - sys_mem_unmap - Exercise 4.6
- 函数作用:上一行就是.jpg
- 操作:
- 检验 va 有效性
- 获取 envid 的进程块
- 直接调用 page_remove 进行映射的删除
int sys_mem_unmap(u_int envid, u_int va) { |
比较好写,但是 MOS 也没调用过,之后可能会有用处吧
为当前进程创建一个子进程 - sys_exofork - Exercise 4.9
int sys_exofork(void) { |
设置进程块 status - sys_set_env_status
见 fork 部分
设置 trapframe - sys_set_trapframe
见 fork 部分
ipc 通信:接收端进程 - sys_ipc_recv - Exercise 4.8
- 函数作用:主动将当前进程阻塞,等待 send 信息
int sys_ipc_recv(u_int dstva) { |
- 这里最后一块:
((struct Trapframe *)KSTACKTOP - 1)指的就是do_syscall那之前创建的用户态 Trapframe,这里把用户态的 v0 寄存器值设为了0,用来代表用户态最初调用的syscall_ipc_recv的返回值为 0
ipc 通信:发送端进程 - sys_ipc_send - Exercise 4.8
- 函数作用:和 recv 配套使用,向已准备好的进程发送信息
int sys_ipc_try_send(u_int envid, u_int value, u_int srcva, u_int perm) { |
ipc 进程通信 - ipc.c
为了在进程间进行数据的传输,我们在 MOS 操作系统中设置了两种传输方式:传输单个 int,共享内存;并且两种方式都集成在了同一个系统调用,也即 sys_ipc_send 和 sys_ipc_recv 两个函数完成,并且两个函数执行时需要先 recv,声明自己已准备好,再调用 send,进行信息的发送。 但是,只设置好了系统调用函数还不足以让我们完成进程间的通信,因为系统需要对发送过程是否成功进行检测,若目标进程未准备好还需要等待,也有许多诸如此类的情况。所以为了方便使用,MOS 在用户态中封装了两个完整的函数用于进行信息传递的全流程,它们位于 user/lib/ipc.c 中,当有通信需求时,直接调用它们就能直观地完成进程通信。 ipc.c 文件开头就有一句这样的注释:User-level IPC library routines,也正好说明了下面两个函数在用户态服务
用户态发送函数 - ipc_send
// Hint: use syscall_yield() to be CPU-friendly. |
- 这里使用的
syscall_yield非常巧妙:如果对方进程未就绪,那在这个时间片中也不可能转换为就绪状态(本时间片一直是本进程运行),那为了避免当前时间片忙等,索性直接归还 CPU,等下一次调度到自己之后再查
用户态接收函数 - ipc_recv
// Hint: use env to discover the value and who sent it. |
- 相比之下,recv 函数内赋值语句较多,因为需要接收一些信息,系统调用函数倒比较简单,单纯调用一次 syscall_ipc_recv 就完事了
用户进程的创建 - fork.c
用户进程调用 fork 函数时,将会创建一个和当前一模一样的新进程:父进程进行一次函数调用,父、子进程都产生一个返回值。父进程返回值为子进程的 env_id,子进程返回值是0,通过返回值不同来标定谁是子进程。 为了实现 fork 函数,我们主要需要补充user/lib/fork.c 中的函数。 实现 fork 的主要流程如下,我们接下来会按顺序介绍(感谢指导书的图.jpg) 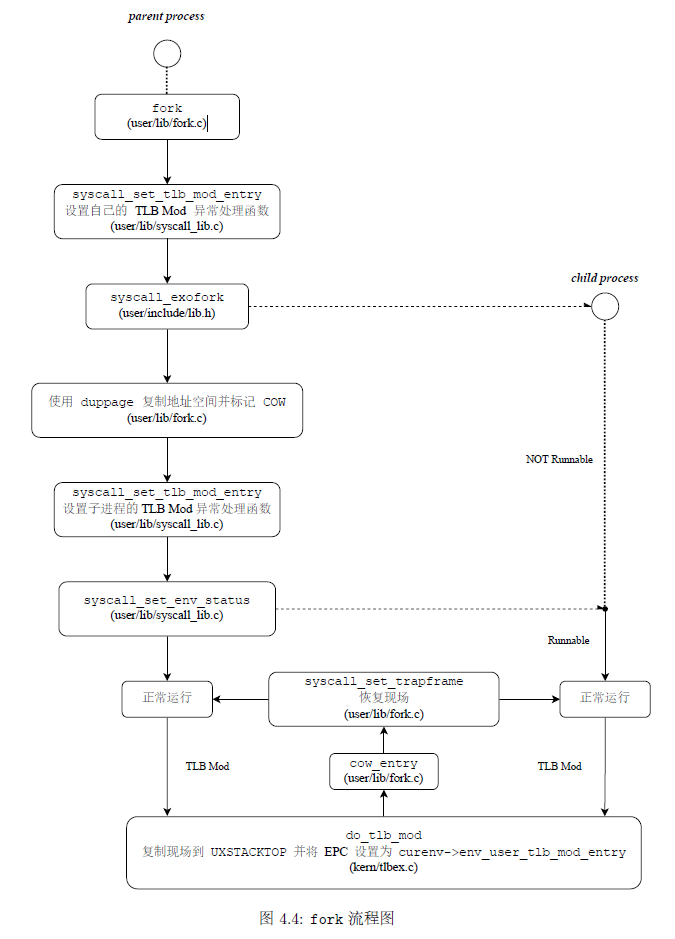
写时复制 COW 与页写入异常
在通过后文提到的 fork 函数创建进程时,父子进程间会暂时共享内存空间,但实际上在写入这两个进程空间时,它们应该互不干扰。那一种直观的做法就是把父进程的所占用的物理页面全都复制一遍插入进子进程中。然而这么做会造成很大的内存开销,同时那些本身不可写的页面还需要白复制一遍。 所以我们引入了一种写时复制机制 COW,用来解决进程创建后的内存共享问题。COW 的解决思路:当父子进程需要修改可写页面内容(PTE_COW = 1)时产生一种异常,它只新复制出该页的内容以供修改,没用到的页面仍旧保持原状。 考虑到给 PTE_D = 0 的页面写入时会产生 TLB_MOD 异常,我们就顺便把 COW 需要的页面标记为 PTE_D = 0, PTE_COW = 1,也进入 TLB_MOD,并在其中中判断是真正的错误写入,还是 COW 触发。
申请子进程的进程控制块 - sys_exofork - syscall_all.c - Exercise 4.9
- 函数作用:为子进程申请一个进程块,并把父进程的内容拷贝
int sys_exofork(void) { |
- 为了避免
syscall_exofork的栈帧在后续写时复制机制建立好之前被错误地更改,导致返回地址被覆盖,我们把syscall_exofork设置为了内联函数,不再创建栈帧,保护了进程地址跳转的正确性。
Upd: 23.5.4
- 在父进程执行这个函数的过程中,会把子进程的 v0 寄存器设置为 0;随后父进程从系统调用中返回并恢复现场,
syscall_exofork的返回值为子进程 env_id,而子进程并没有执行这个函数,只是在被调度时才首次开始运行,恢复进程控制块中存放的 trapFrame,其中的 EPC 也令进程从 fork 函数中的syscall_exofork结束后运行,这时存放于 v0 寄存器的返回值是 0,看起来好像子进程执行了这个函数并返回了 0。这就是syscall_exofork实现两个不同返回值的过程。
写时保护函数 - duppage - Exercise 4.10
- 这个函数功能比较单一,但考虑的情况比较多
- 函数功能:将符合要求的页面
PTE_D置0,PTE_COW置1
/* Hint: |
- 先给子进程映射的原因可以看这里

如果先给父进程加PTE_COW,然后修改了该页,该页将进行写时复制,父进程指向新的页,而新页没有被加上PTE_COW。此时再map子进程,子进程该页加上PTE_COW位而父进程没有。在随后程序运行中,若父进程进行修改,由于缺失PTE_COW,导致无法进行写时复制,因此子进程的运行出现错误(子进程该页本来不该被改,但却由于父进程被改而一起改了)。
设置子进程 TLB_Mod 处理函数 - sys_set_tlb_mod_entry - Exercise 4.12
在 “写时复制 COW 与页写入异常” 一节中,我们已经知道,MOS 处理写时复制的时间是在进入 TLB_Mod 异常之后的,现在我们需要先设置 TLB_Mod 的处理函数。注意这里的处理函数可以来自用户态。 这样,在后续触发写时复制机制时,就能直接从用户给出的函数开始执行,处理异常了。
int sys_set_tlb_mod_entry(u_int envid, u_int func) { |
- 这里的 func 指的实际是异常处理函数的入口地址,当触发异常时,
do_tlb_mod会将 EPC 设置为 func 的值,同时退出异常,借此执行 Mod 异常的处理。
TLB_Mod 响应函数 - do_tlb_mod - Exercise 4.11
- 当系统发生 TLB_Mod 异常后,首先进入这里的 handler,设置好跳转后再
ret_from_exception回到用户态,执行真正响应异常的用户态函数,最后再从该函数中返回受害指令
|
用户异常栈
- 前面在栈帧一小节中已经提到了用户栈、内核栈和他们的作用,这里还要提到一个新的栈帧:用户异常栈(
va = UXSTACKTOP),它充当在用户态中处理异常所用到的函数的栈,这里就是页写入异常处理函数的栈 - 用户异常栈和内核栈功能类似,都是在发生异常时开始使用,同时都从对应栈的 TOP 开始记录,看起来用户异常栈应该也允许异常重入。
if (tf->regs[29] < USTACKTOP tf->regs[29] >= UXSTACKTOP) { |
- 这里的 Step2 为什么要做这样一系列操作呢?因为这个C语言函数结束后,会通过汇编语言的
ret_from_exception直接返回 EPC。因为没有显式的函数调用,所以编译器并不会为后续跳转到的处理函数创建栈帧,这里我们需要手动创建用户异常栈中的函数栈帧,供异常处理函数使用
TLB_Mod 的实际处理 - cow_entry - Exercise 4.13
没错,这个函数就是刚才提到的用户态异常处理函数,执行 ret_from_exception 后会从这里继续执行。最终在这里完成写时复制页面的复制,并返回用户态继续执行受害指令。
/* Overview: |
-
cow_entry的实际作用就是建立了一个受害页面在页表中的新映射。这个映射只有权限位不同,当再次写入受害 va 所在的页面时,会得到正确的 perm。 - 旧:UCOW 空,va 会触发写时复制(申请物理页面,复制va-> UCOW) 过程中:UCOW va内容,va会触发写时复制 结束:UCOW 空,va不会触发写时复制,指向UCOW 申请得到的那个物理页面
子进程控制块设置 - sys_env_set_status - Exercise 4.14
- 启动新进程的最后一步:执行完所有的设置后,最后通过这个函数将子进程插入待调度队列,正式启动子进程
int sys_set_env_status(u_int envid, u_int status) { |
Upd: 23.5.5
需要在 Step4 中额外留意 status 的变化,如果变为 RUNNABLE 则需要加入至调度队列,如果 NOT_RUNNABLE 则需要移出,因为在 Lab3 的 schedule 函数中,我们已经要求所有变化进程状态的函数需要负责维护 env_sched_list,在这里就需要将 NOT_RUNNABLE 的函数移除。感谢芬海哥哥捏,指出了这里的错误 以上,就是创建一个子进程所需要的全部步骤,那么 fork 函数,实际上就是这些函数的结合
子进程的创建 - fork - Exercise 4.15
int fork(void) { |
- 在这里唯一需要考虑的点就是 Step3 中 for 循环的起止条件、if 的判断条件
- i 在这里表示的是用户态可用虚拟内存的页号:
UTEMP >> 12,是正式可以被用户态使用的第一个页面,而USTACKTOP >> 12则是最后一个 - if 的判断条件则是:i 对应的虚拟页面是否能在页表中查到有效的映射,如果有,说明它需要考虑是否需要标记
PTE_COW。
一言
Lab4 到这里可算是结束了,这个 Lab 给人最直观的感受就是码量的上升与内核态/用户态函数的协同更复杂了。这篇文章唠唠叨叨说了这么多,也是想尝试从更深一层去了解 MOS 运作的机理,而不是简单的完成几个填空,知晓表象就弃若敝履罢了。文章实际上没有想做什么分享,算是自我总结吧,因为自己都不知道对不对(笑 还剩两个 Lab,希望能把习惯保持下去
附录
一些没用上的函数,贴一下
syscall_all.c
打印字符至控制台 - sys_putchar
直接调用了 printcharc 函数,和 printk 效果类似吧
void sys_putchar(int c) { |
打印用户空间的定长字符串 - sys_print_cons
先检查了地址是否位于用户区域,然后检查了长度是不是正的,最后循环调用了 printcharc 函数
int sys_print_cons(const void *s, u_int num) { |
获得运行中进程块的 id - sys_getenvid
就一句话,但是好像还没有在 MOS 中使用过
u_int sys_getenvid(void) { |
销毁进程 - sys_env_destroy
只有直系进程才能进行销毁(自己也行)
int sys_env_destroy(u_int envid) { |
读入字符 - sys_cgetc
直接调用了函数 scancharc ,此时会让系统处于忙等状态,直至接收到字符返回
int sys_cgetc(void) { |





